تحلیلها (Analytics)
صفحه تحلیلها، داشبورد مانیتورینگ دقیق و گزارشهای کاربردی از نحوه مصرف منابع سرویس هوش مصنوعی را ارائه میدهد. این بخش با هدف ارزیابی عملکرد سیستم، بهینهسازی ترافیک و مدیریت ساختار هزینهها طراحی شده است و دادهها را در دو سطح شاخصهای کلیدی و نمودارهای تفکیکی نمایش میدهد.
۱. شاخصهای کلیدی عملکرد (Metrics)
در بالاترین بخش داشبورد، سه متریک مهم، وضعیت کلی مصرف شما را نشان میدهند:
- میانگین زمان پاسخ: میانگین زمان صرفشده (بر حسب میلیثانیه) برای پردازش و دریافت خروجی از مدلهای هوش مصنوعی. این شاخص برای بررسی تاخیر (Latency) شبکه و ارزیابی سرعت پاسخگویی سرویس ضروری است.
- توکنهای استفاده شده: مجموع دقیق توکنهای پردازششده (شامل پرامپت ورودی و پاسخ خروجی) در تمامی فراخوانیها. این عدد مبنای اصلی محاسبه هزینههای شماست.
- تماسهای API: تعداد کل درخواستهای موفق ارسالشده به سمت اندپوینتهای سرویس.
۲. نمودارهای تحلیلی و گزارشها
بخش پایین داشبورد، جزئیات مصرف را در بازه زمانی ۷ روز گذشته و در قالب سه تب گرافیکی مجزا تحلیل میکند:
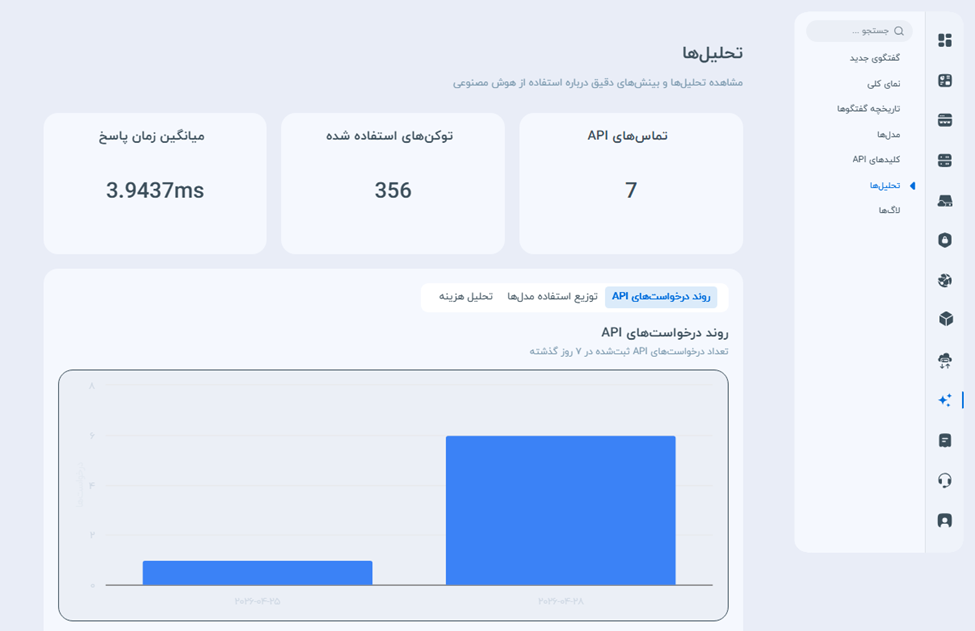
- روند درخواستهای API: یک نمودار میلهای که حجم درخواستهای ثبتشده را به تفکیک روز نمایش میدهد. بررسی این نمودار برای شناسایی روزهای پرفشار (Traffic Spikes) و درک الگوی بارگذاری سیستم روی سرورها کاربرد دارد.
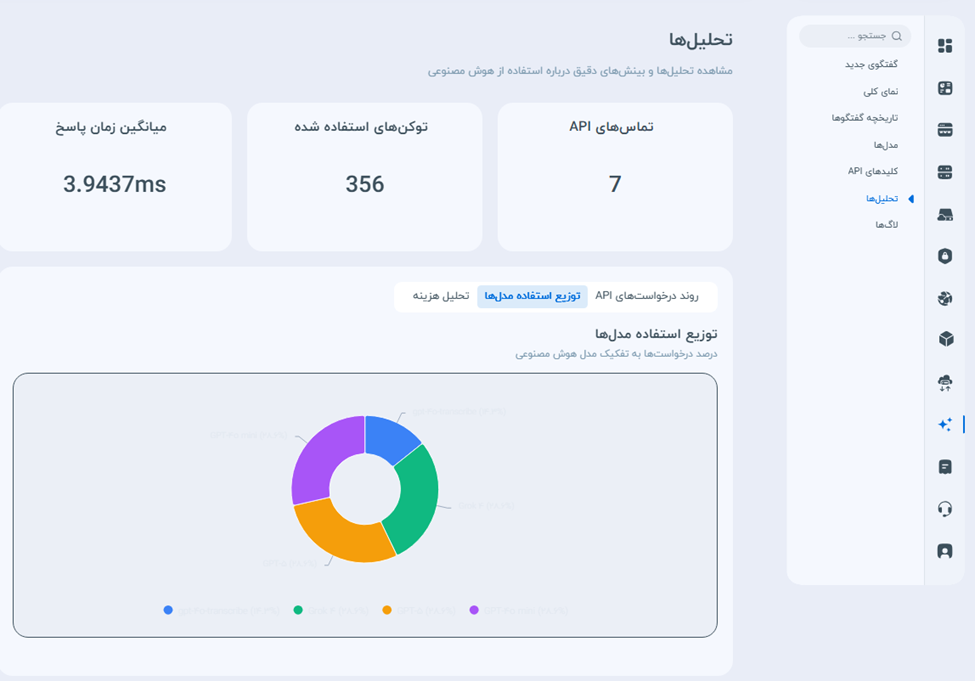
- توزیع استفاده مدلها: یک نمودار دایرهای که سهم هر مدل هوش مصنوعی را از کل درخواستهای ارسالی به صورت درصدی مشخص میکند. این گراف به شما نشان میدهد که ترافیک سرویسهای شما بیشتر به سمت کدام مدلها (مثلا مدلهای سریعتر یا مدلهای دقیقتر) هدایت شده است.
- تحلیل هزینه: یک نمودار خطی که روند تغییرات هزینههای روزانه شما را مانیتور میکند. این ابزار به شما اجازه میدهد تا شیب مصرف بودجه خود را ردیابی کرده و در صورت مشاهده رشد غیرمنطقی هزینهها، بلافاصله محدودیتهای لازم را روی کلیدهای API اعمال کنید.